Unser RideProof-Verkehrsmonitor misst an 178 Punkten zwischen Nordsee und Südtirol — knapp 1,5 Millionen Messwerte bisher. Daraus entstehen automatische Verkehrsberichte: Stau-Spitzen, die freiesten Motorradstrecken, beste Fahrfenster. Dieser Artikel legt alles offen: jede Datenquelle, jeden Abruf-Zyklus, jede Berechnungsregel — und wo genau KI beteiligt war (und wo bewusst nicht).
Warum wir eigene Verkehrsdaten sammeln
Wer Motorradtouren plant, will zwei Dinge wissen: Wo stehe ich im Stau? Und wichtiger: Wo fahre ich frei? Öffentliche Verkehrsmeldungen beantworten nur die erste Frage — und auch die nur grob. Also haben wir angefangen, selbst zu messen. Erst 128 Punkte an einem Wochenende, inzwischen ein dauerhaft laufender Monitor, der rund um die Uhr Daten sammelt und daraus automatisch Berichte erzeugt.
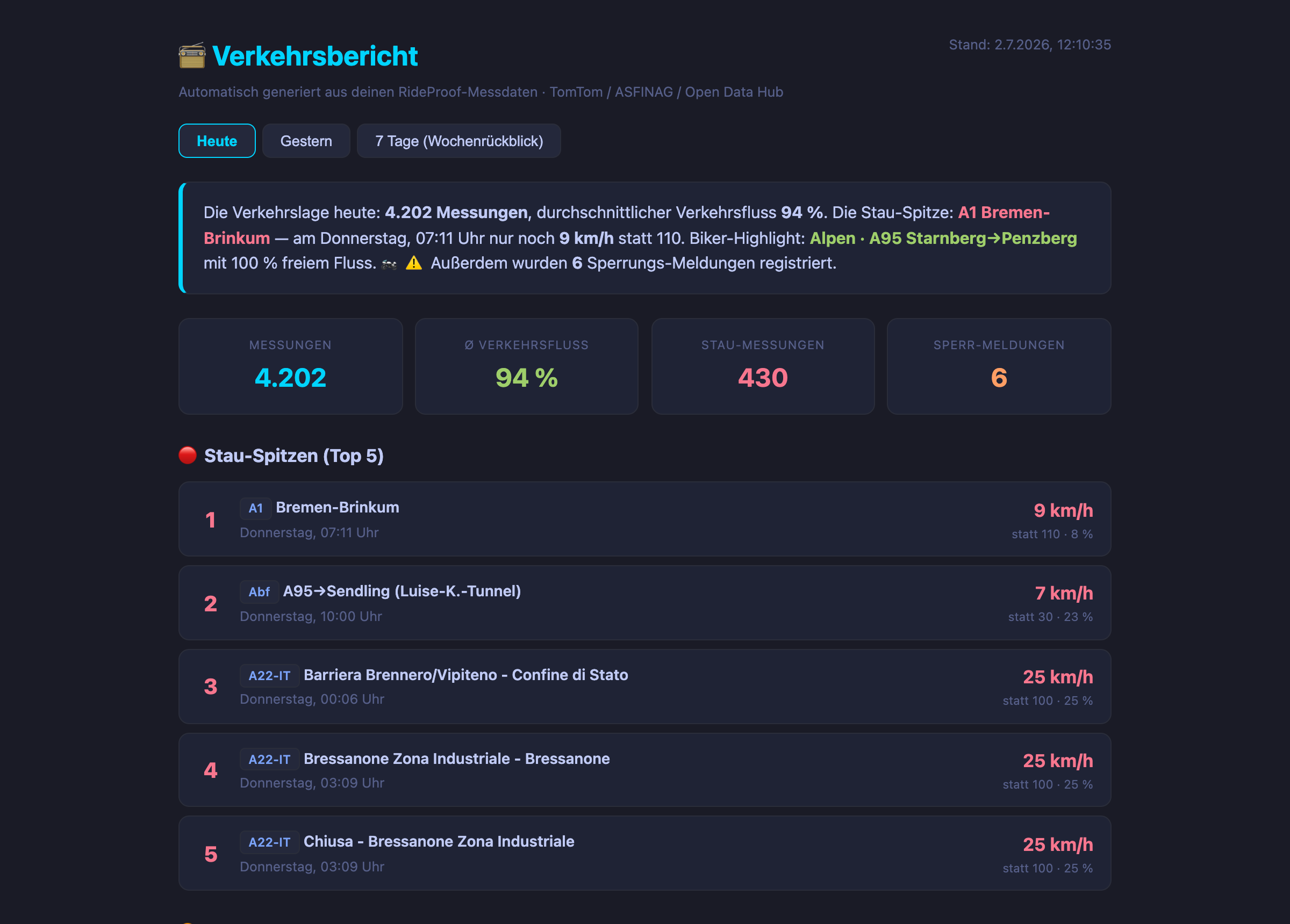
Das Ergebnis sieht so aus:
Die Datenquellen — vollständig offengelegt
Jeder Wert in unseren Berichten lässt sich auf eine dieser sechs Quellen zurückführen:
| Quelle | Was wir abrufen | Abdeckung | Zugang / Lizenz |
|---|---|---|---|
| TomTom Traffic Flow API | Aktuelle Geschwindigkeit + Freeflow je Straßensegment | Deutsche Autobahnen, Stadtpunkte, Motorradstrecken | API-Key, Kontingent-basiert |
| ASFINAG (Österreich) | Reisezeiten A12/A13 (Brenner-Korridor), DATEX-II-Format | Inntal- und Brennerautobahn | Open Data, CC BY 4.0 |
| Open Data Hub Südtirol | Strecken-Verkehrslagen der A22 | Brenner bis Verona, 102 Abschnitte | Open Data, frei |
| Bright Sky (DWD) | Aktuelles Wetter | 19 Wetterzonen entlang der Strecken | Open Data, frei |
| Open-Meteo | Wetter-Vorhersage | dieselben Zonen | Open Data, frei (nicht-kommerzielle Nutzung) |
| Umweltbundesamt | Luftqualität (4 Schadstoffe) | 9 Messstationen | Open Data, frei |
Wichtig zur Einordnung: Wir verkaufen diese Daten nicht weiter. Sie fließen ausschließlich in unsere eigenen Analysen und Berichte. Die Open-Data-Quellen werden mit Quellenangabe genutzt, die TomTom-Daten im Rahmen des regulären API-Vertrags. Alles selbst finanziert — hier gibt es keine bezahlten Kooperationen.
Die Erhebungszyklen — wer wird wie oft gemessen?
178 Messpunkte im Minutentakt abzufragen wäre weder nötig noch bezahlbar. Der Monitor arbeitet deshalb mit rotierenden Gruppen, deren Takt sich nach der Dynamik der Strecke richtet:
| Gruppe | Punkte | Normaltakt | Besonderheit |
|---|---|---|---|
| Österreich / Italien (A12, A13, A22) | 110 | ca. alle 15 Min | Open Data — kostet kein Kontingent |
| Deutsche Autobahnen (A1–A99) | 64 | stündlich | Rush-Modus: 6–9 und 16–19 Uhr alle 20 Min |
| Stadt / Ring / Abfahrten | 16 | alle 45 Min | — |
| Motorradstrecken (Alpen, Schwarzwald, Eifel, Harz, Sauerland, Fränkische) | 34 | alle 90 Min | pausiert im Berufsverkehr zugunsten der Autobahnen |
| Wetter | 19 Zonen | alle 30 Min | — |
| Luftqualität | 9 Stationen | stündlich | — |
Das Tages-Budget liegt bei 4.800 API-Abrufen — real nutzen wir dank der Rotation nur etwa 8 Prozent davon. Sparsamkeit ist hier kein Selbstzweck: Sie zwingt zu der Frage, welche Messung wirklich Information bringt. Eine Alpenstrecke um 3 Uhr nachts alle 5 Minuten abzufragen bringt keine.
Vom Rohwert zum Bericht — die Rechenregeln
Der Kern jeder Bewertung ist ein einziger Quotient: aktuelle Geschwindigkeit ÷ Freeflow-Geschwindigkeit. Freeflow ist das Tempo, das auf dem Segment bei freier Strecke üblich ist — es kommt direkt aus den Quelldaten, wir schätzen es nicht selbst.
- ab 85 % → freie Fahrt
- 60–85 % → verlangsamt
- unter 60 % → Stau
Der Tages- und Wochenbericht entsteht dann aus einfachen, nachlesbaren Abfragen über diese Werte: Die „Stau-Spitze" ist das Minimum des Quotienten im Zeitraum. Die „Biker-Highlights" sind die Motorradstrecken mit dem höchsten Durchschnitts-Quotienten. Die „besten Fahrfenster" sind die Stunden mit dem besten Netz-Durchschnitt. Kein Modell, keine Magie — Prozentrechnung und Sortieren.
Wo KI im Spiel ist — und wo bewusst nicht
Hier wird es uns besonders wichtig, sauber zu trennen, denn „KI-generiert" kann zweierlei bedeuten:
Gebaut mit KI: ja, fast vollständig. Der Datensammler, die Dashboards, die Ensemble-Graphen und der Berichts-Generator sind in Zusammenarbeit mit einem KI-Coding-Agenten (Claude) entstanden — im Dialog, Feature für Feature. Der Verkehrsbericht aus diesem Artikel wurde an einem Nachmittag gebaut. Der Prompt dafür war sinngemäß dieser:
„Könnten wir eine Art Wochenrückblick erstellen — sowas wie ein Verkehrsbericht, basierend auf den Daten, die wir haben? Wir schauen uns die Spitzen an, und natürlich auch die Strecken, die besonders gut zu fahren sind. Gerne als Wochenbericht oder Tagesbericht, mit den absoluten Highlights."
Mehr war es nicht. Der Agent kannte das Datenbankschema, schlug die Struktur vor (Stau-Spitzen, Biker-Highlights, Fahrfenster) und setzte sie um. Wer so etwas nachbauen will: Genau diese Art von Prompt — Ziel beschreiben, Datenlage benennen, Beispiele geben — funktioniert erstaunlich zuverlässig.
Berichte zur Laufzeit: bewusst OHNE Sprachmodell. Die Berichtstexte („Die Stau-Spitze: A1 Bremen-Brinkum …") entstehen aus festen Satzschablonen, die mit den echten Zahlen gefüllt werden. Kein Sprachmodell formuliert hier frei — und das ist Absicht: Ein Verkehrsbericht darf nicht halluzinieren. Jede Zahl im Bericht ist eine Datenbankabfrage, die man nachrechnen kann.
Die Screenshots in diesem Artikel sind übrigens genau deshalb statische Bilder mit Zeitstempel — bewusst keine Live-Einbindung. Was ihr hier seht, ist ein festgehaltener, überprüfbarer Zustand, kein sich änderndes Fenster in eine Datenbank.
Grenzen — der ehrliche Teil
- Messpunkte sind Stichproben. 178 Punkte bilden nicht jede Strecke ab. Ein Punkt am Irschenberg sagt nichts über die A8 bei Pforzheim.
- Freeflow ist eine Referenz der Quelle, keine amtliche Größe. Verhältniswerte verschiedener Anbieter sind nicht 1:1 vergleichbar.
- Rotations-Takte bedeuten Lücken. Eine deutsche Autobahn wird außerhalb des Berufsverkehrs stündlich gemessen — ein 20-Minuten-Stau kann durchrutschen.
- Nachterfassung ist dünner als tagsüber — die Wochenstatistik gewichtet Stunden deshalb nicht um.
Und wozu das alles?
Diese Daten sind kein Selbstzweck. Sie fließen in dieselbe Frage, um die sich bei uns alles dreht: Wann und wo fährt man am besten Motorrad? Der Verkehrsmonitor sagt, wann die Anfahrt frei ist und welche Kurvenstrecke gerade leer — und Kurvenfokus analysiert danach, wie du sie gefahren bist: Kurve für Kurve, mit Schräglage, Score und Heatmap. Beides zusammen ist unser Weg, Motorradfahren messbar besser zu machen.
Fragen zur Methodik? Schreib uns — die Antwort landet dann hier im Blog. Und wer die Verkehrsdaten-Serie von Anfang lesen will: Teil 1 — Von 128 Punkten zu 57 Millionen Stundenwerten.